If you’re old school, you can find a raw HTML version of this post here
This is a fairly long, stream-of-thought post about how I currently (Sunday Feb 4, 2024) feel about the broader ML/NLP/IR ecosystem and its future. Everything here’s on-the-fly opinion and can & will change.
In summary: I think ML developments are incredibly exciting, and we need to continue to work on bridging the gap between ML-as-a-commodity-for-ML-practitioners to ML-as-a-commodity-for-everyone. This hopefully can happen with a mix of better products and more open source projects.
I’m super excited by the discussions I’ve had with the team at Answer.AI and just as excited to announce I’ll be joining them next month. I think it’s truly the ideal place to contribute to making this happen!
What a long, strange… month? It’s been
The last few months have been fairly strange and fast-paced, to say the least.
In no particular order, I’ve moved to the Basque country (with an eye to Japan or Singapore in the near future!), eloped to Gibraltar, released RAGatouille and, most recently, gotten a bad case of COVID which I’m not fully recovered from a month out, and quit my main employment.
While those are all significant, this blog post is (obviously) about RAGatouille, and the whirlwind releasing it has unleashed.
Over the course of a month, I’ve essentially had 8am to 2am days, fixing things and taking various calls. I’ve found myself with the very first-world problem of being approached with VC offers, and trying to navigate the implications. The whole experience ultimately surfaced a lot of questions I’d been thinking about for a while.
We’re all still learning Machine Learning
For a long time now, I’ve been of the opinion that the democratisation of ML has an ecosystem problem. “Problem” is arguably too strong a word, to be fair: it’s all very new and developing rapidly, and strides are being made everyday.
But I think we’re definitely seeing a massive gap between “those-who-know”, us nerds passionate enthusiasts having worked in the field for a good few years, endlessly scrolling twitter and desperately trying to filter the noise, with moderate-to-good success. And “those-who-don’t-know”, which are, truthfully, the absolute majority of developers.
Being part of the latter group, though, is not something to be ashamed of. There’s just so much going on that if you’re a computer vision expert, you’re probably a don’t-knower for NLP or IR, and vice-versa.
Ultimately, ML as a whole rarely feels like pure research: to me, it’s an R&D field, although with heavy emphasis on the R rather than D.
ML is a commodity not yet commoditised
So what does this look like if you zoom out: what if you’re not even in an ML field like CV, but are a senior backend expert?
There’s absolutely no way you can be in-the-know about everything going on in ML when people who spend ten hours a day reading papers aren’t.
But ML is now everywhere. It’s just assumed that it will seep through to every sort of application. Everyone wants a chatbot. Everyone wants to use AI here and there. To the point that we now expect every single tech practitioner to use some sort of AI tool, or to do so in the (near) future.
This is pretty apparent if you’ve ever worked with established companies who aren’t historical AI players. There is a very high chance you’ll have heard complaints about having set up an AI lab, a Data Science Department, an ML Strike Team, an R&D League of Extraordinary Developers, or a million other monikers, but nothing has made it to production.
Or worse: it’s made it to production, but it’s not very good. Executives are unhappy, the development team is demotivated, the project might get shelved, and a problem that ML could’ve solved remains unsolved.
And it’s not because of one particular glaring issue, but rather, a million small flaws that’d be immediately apparent to the arXiv-reading, Colab-tinkering GPU middle class.
This is rarely the fault of the development team: it’s simply unrealistic to expect experts from other domains to have this level of exposure to such a rapid moving field.
ML is infrastructure, it needs user-friendliness built on top.
Historically, ML has needed infrastructure. It’s been an object of research, focused on trying to figure out ways to make it work with whatever tools we had.
It feels like this has changed now. Yes, ML still needs infra, but we’ve also reached the point where it itself is now infrastructure.
By this, I mean that it’s now part of the software stack that is to be built upon in order to build great user-facing applications.
A good analogy for this, I think, is Redis.
If my only way to dabble with in-memory key:value storage was to read a few related papers, find github implementations and figure out how to use them, I probably wouldn’t bother. Instead, I’d stick to what I know and is heavily documented, and figure out a way to make my data work with SQL.
When I use Redis, I’m not expected to know about the Computer Science literature surrounding memory allocation. I’m not expected to understand how it so efficiently scales and fetches stored blobs. All I’m expected to know is that I can store some data at a given key and I can retrieve it really quickly if I let Redis do its thing.
This doesn’t mean that there aren’t distributed systems experts and C programmers trying to make Redis work. What it does mean is that there’s a difference between an applications developer and an infrastructure developer, and that these two require distinctly different skillsets.
Moreover, it also doesn’t mean that, as a developer, I’m not free to take an interest into how this actually works. Maybe I am even going to need to tweak it to better suit my own use. But this interest only becomes possible because I had access to an easy-to-use, relatively intuitive application in the first place. (funnily enough, my first open source contribution was a very minor fix to Redisearch’s python client python 3 compatibility)
I think this should be the same for ML.
Moreover, and I’ll probably write more on this in the future, I think this concept of taming the new reality that “ML is infrastructure” applies to both developer tools and user-facing applications.
When looking at the product landscape, it’s obvious that we’re also still in the early days of figuring things out in terms of just how we should be building ML-native user applications. We’re still all on the journey of figuring out how to do better than shoehorning into existing applications, but also of understanding how to present it in a way that just makes sense to users. To the end user, ML isn’t an end, it’s the means to one.
RAGatouille and the example of ColBERT
I think RAGatouille is a great example of this. As of right now, it’s not a particularly rich library, but the interest around it really highlights how present the demand is for anything that lowers the barrier to entry.
IR isn’t NLP isn’t CV isn’t RL isn’t LLMOps isn’t Recsys isn’t ML isn’t …
All those acronyms, I think, are already a good way to drive the point that we’ve come to expect a lot of baseline knowledge.
ColBERT, and late-interaction retrieval in general, isn’t all that new. It’s from early 2020 (also known as Year 3, After-Attention is All You Need), which feels like a different era altogether. The state-of-the-art text generator, back then, was GPT-2. However, it has never been really friendly to use for non-IR folks.
Information Retrieval (IR), as a research field, is adjacent but quite different to NLP. There’s a strong emphasis placed on rigour, sometimes to an extreme extent, and, as a natural result, the research code, while available, is frequently over-engineered and can feel overwhelming to outsiders.
One example of this is benchmarking. A common question is:
“if X model is so good, where is it on MTEB?”
MTEB, as you may know, is the Massive Text Embedding Benchmark.
The question above makes complete sense if you’re not familiar with IR. Most of your exposure to retrieval is likely going to be various blog posts, and you’ll probably know that so-called “dense” embeddings are used for retrieval, and evaluated on MTEB.
But MTEB isn’t solely a retrieval benchmark: it evaluates models on a wide-range of tasks, such as textual entailment, text similarity, classification, and, yes, retrieval. But the fact that it contains many other tasks already means you won’t see retrieval models on the leaderboard, as they’re simply not made for them.
Potentially even more importantly, MTEB isn’t considered a very useful measurement of real-world retrieval performance, because it has public training data and is specifically optimised for.This is such a given to IR researchers that you’ll even see a lot of papers simply not evaluating on it.
I won’t go on much more about retrieval in this post, but I think it’s important to point this out. While all this may seem obvious to those well exposed to the field, there’s actually quite a deep amount knowledge needed to even get into the conversation:
- what’s in-domain vs out-of-domain?
- why is a model doing so well in benchmarks not good for me?
- how do I try the better ones?
- actually, how do I even find out what the better ones are?
- what are the metrics I should be on the lookout for, I’ve never heard of ndcg?
- …
RAGatouille as a gateway
RAGatouille, in this context, tries to partially address this problem. It’s been common knowledge among search practitioners that ColBERT is really powerful.
In fact, it’s a mainstay at IR conferences, either as the state-of-the-art, as the thing you seek to improve, or as the go-to really strong baseline to prove your new approach is better.
It’s used or explored by virtually every search-related researcher, startup and company.
However, as I discussed above, we’ve reached a point where ML/AI is now infrastructure, to be used by developers outside its traditional user base, naturally lacking the accumulated knowhow of domain experts.
As a result, it was rarely brought up in the main RAG (Retrieval-Augmented Generation, i.e. retrieving relevant documents to give as context to language models) discourse, where single-vector embeddings are omnipresent.
There’s multiple reasons for this, but the main one is probably that ColBERT, like most research projects, is somewhat usable but definitely not approachable. There’s a lot to know to get started, but there’s even more knowledge needed to know why you should get started.
When I started working on RAGatouille, I likened this (on a much, much smaller scale!) to the release of BERT & the role of HuggingFace in a small twitter exchange.
In short, I think that every tool, to become successful, needs to be a certain combination of powerful, approachable and usable. Even something as major and powerful as BERT experienced a slow start, before blooming when HuggingFace made it the latter two with pytorch-pretrained-bert (the proto-transformers library).
Omar Khattab (Twitter), the amazing researcher behind both ColBERT and DSPy has a great way of describing what RAGatouille does in relation to the previously existing ColBERT landscape:
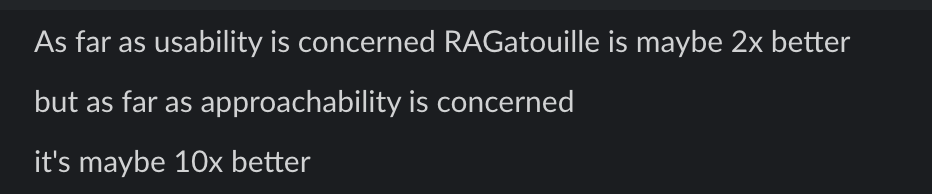
I think he’s right on point, and I’m very happy that my contribution has been received this way. ColBERT has always been powerful, and used by specialists. To echo what I mentioned earlier, RAGatouille’s contribution has been to bridge the excellent Research work with the constraints of Development, making it considerably simpler to build upon ColBERT.
I could probably write endlessly about the future of RAGatouille in relation to this, but let’s leave it at that for now!
Mini-segue: Research vs Abstraction
Interestingly, I think another of Omar’s major contributions, DSPy is a similar situation, on a much larger scale. To me, it feels like a major paradigm change in allowing ML to be used as infrastructure for all sorts of applications, but it’s still in the early stages, and therefore missing the usability/approachability factors that will make it part of every developer’s toolkit.
A while back, I doodled this to help me think about the ecosystem while chatting with Omar. My point of view is that every tool sort of falls somewhere in a Research to Abstraction/Library scale, with what I’d call Toolkits right in the middle.
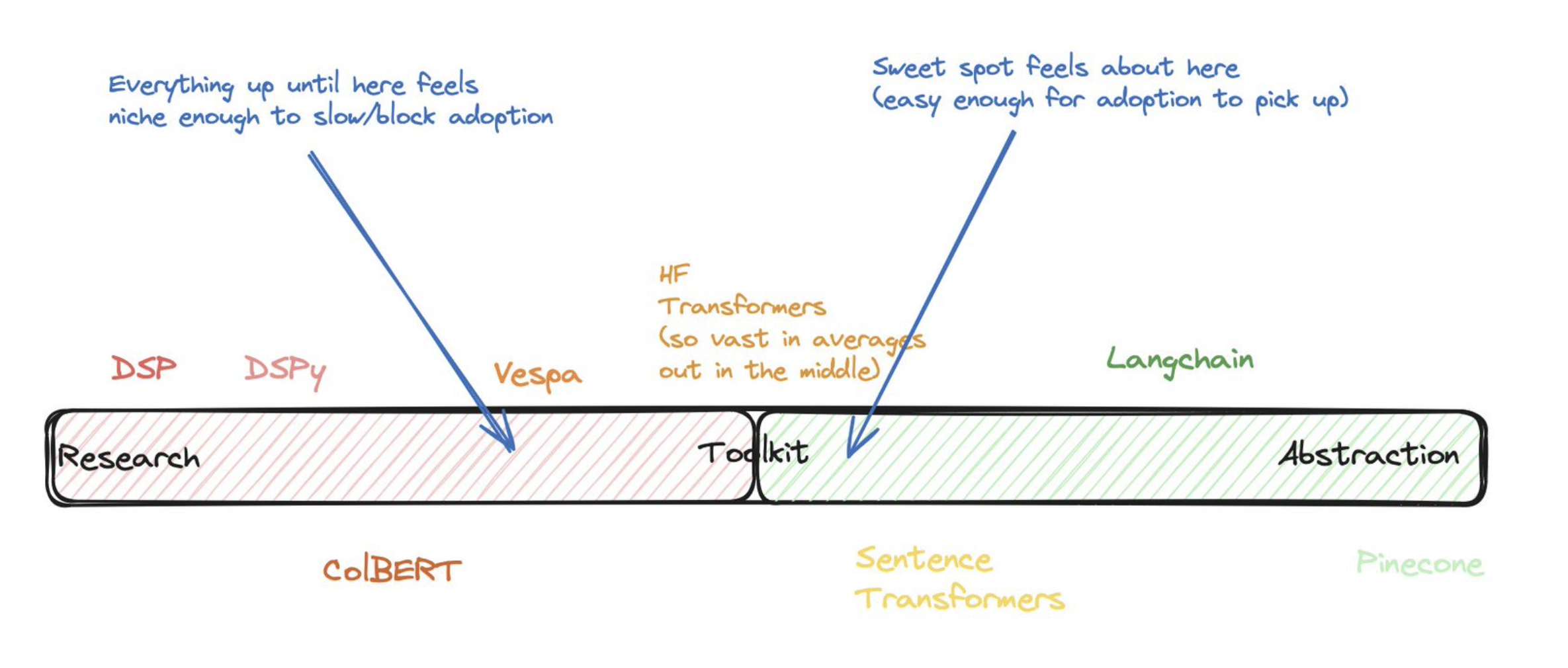 doodle presented in its original state, typos included
doodle presented in its original state, typos included
I’m not sure I fully stand behind where I placed every example on this scale, especially as the landscape changes quickly, but I often still find myself referring to this “mental scale” when building something: the further towards Research something feels, the more powerful/extensible it is, at the cost of the approachability that being an Abstraction/Library provides.
Incentives are tough
So then, if the problem is so clear, why don’t we just go and fix it?
There’s a lot of reasons here, to the point where exhaustively listing them would take quite a long time.
However, there are a few main things to point out.
The first is that I’m just a single person pointing out what needs to be done, from my point of view. The odds that I’m completely right are close to 0%. I’d like to think that this is also true about the odds that I’m completely wrong, though.
The next one is that it’s not too tough to point out what you think is a problem. Criticism requires a good markdown editor and not much else. It’s much harder to come up with good solutions. People are actively working towards addressing this. ML as this infrastructure component is a very new thing. It takes time and effort for new paradigms, approaches and products to fully take shape, but we are heading there.
Finally, and I think this is the biggest one: it’s hard to get incentives to align to make this happen.
I’ve been thinking about this last one a lot. I’ve been in touch with a lot of VCs to chat about my vision for RAGatouille’s place in the “IR applications” ecosystem, and potentially starting a company to work towards it.
The problem is that in this situation, my own incentives would be drastically different to the ones of my investor. I’d like to build “slowly”, explore ideas, see some fail, see others grow, and keep adding new things. Someone who’s handed me a $500k cheque would like me to find Product-Market fit, and, as soon as I find it, throw everything at it and get to profitability. A very fair ask for their money, but a toxic one for ecosystem development.
(Of course, this doesn’t always happen, and HuggingFace is a great example of this, but it happens more often than not)
Academia also faces a similar incentive wall. As it currently functions, it doesn’t favour the creation of applications, which is what an ecosystem needs. Eric Gilliam’s Answer.AI guest post about the great R&D labs of history illustrates this point superbly well, so if this is of interest, I’d direct you towards it. This is not to say that academic work isn’t good or important (it very much is!), simply that it’s not sufficient.
Joining Answer.AI
And finally, what was originally the main point of writing this, before I realised I’d more to write than I thought: I’ll be joining Jeremy Howard & Team at Answer.AI on the 4th of March.
Truthfully, this came completely by chance. I’ve been a fan of Jeremy Howard’s work for a long time, and fast.ai has long been a big inspiration on how I try to think about code. When Answer.AI was announced back in December, I really enjoyed the stated philosophy, and thought it was a much needed effort amidst the current landscape.
While discussing RAGatouille’s next steps a few weeks ago, Omar offered to introduce me to J. Howard, and I was more than happy to accept!
At the same time, I’d done a lot of thinking about just where I wanted to take things. Obviously, working full-time at a day-job then at a side-project-turned-night-job wasn’t something very sustainable in the long run. Consulting and maintaining OSS on the side was an option, or entertaining the VC discussions to try and build a company was another.
But truthfully, for the reasons in this post and more, neither option felt ideal.
Meeting Jeremy and discussing the possibility of joining Answer.AI felt like the kind of timely coincidence you just have to embrace.
Even if I limit my thinking to “better retrieval” (which is a limit I don’t intend to stick to!), it feels like there’s a million ways forward, a million applications to be tried, and a million ways to make it accessible in ways that hopefully could meaningfully improve people’s experiences.
I feel like the philosophy of Answer.AI is about as close to a perfect match to my own as you’re going to get. We’re currently at a very unique and exciting point in history for AI work. We don’t know much about what will come next, and even less about what the path forward looks like. What I do know for sure is that we need to tinker and try new approaches in order to get there.
ML is infrastructure now, and it’s infrastructure whose total market size is just about everyone, we just need to figure out how that happens. I think Answer.AI is going to be the perfect place to fail to do this until we succeed.